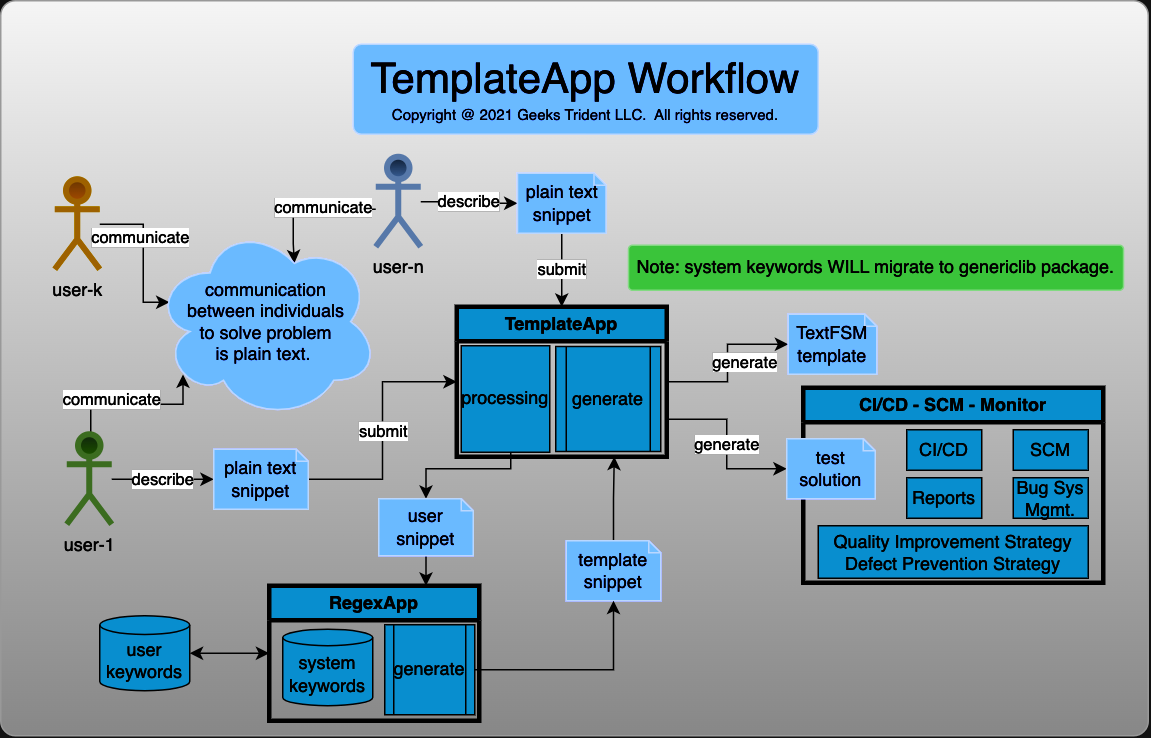
Welcome to TemplateApp Docs
TemplateApp is a closed source Python package that is used to help individuals to generate TextFSM template by using plain text. TemplateApp offers two licenses: Non-Commercial-Use License and Commercial-Use License
Non-Commercial-Use License
| Development Status | ALPHA |
|---|---|
| Availability | Online App by www.geekstrident.com |
| Installation | N/A |
| Cost | Free of Charge |
| Ad-Free | With Ad |
| Test Solution | N/A |
| Tech Support | N/A |
| Integration | N/A |
Commercial-Use License
| Development Status | ALPHA |
|---|---|
| Availability |
Online or Offline App by
CLIENT DEPLOYMENT
or
Online App by PARTNER / THIRD-PARTY services |
| Installation | Github or Offline-package |
| Cost | Cost per Strategy |
| Ad-Free | YES |
| Test Solution | YES |
| Tech Support | YES |
| Integration | YES |
Benefit of Using TemplateApp
Mitigating Human Error
Unintended Action Based Error (Slip)
Assuming user1 wants to use WebTemplate application to solve this problem. First, user1 edits the output by adding a group of hyphen line as below
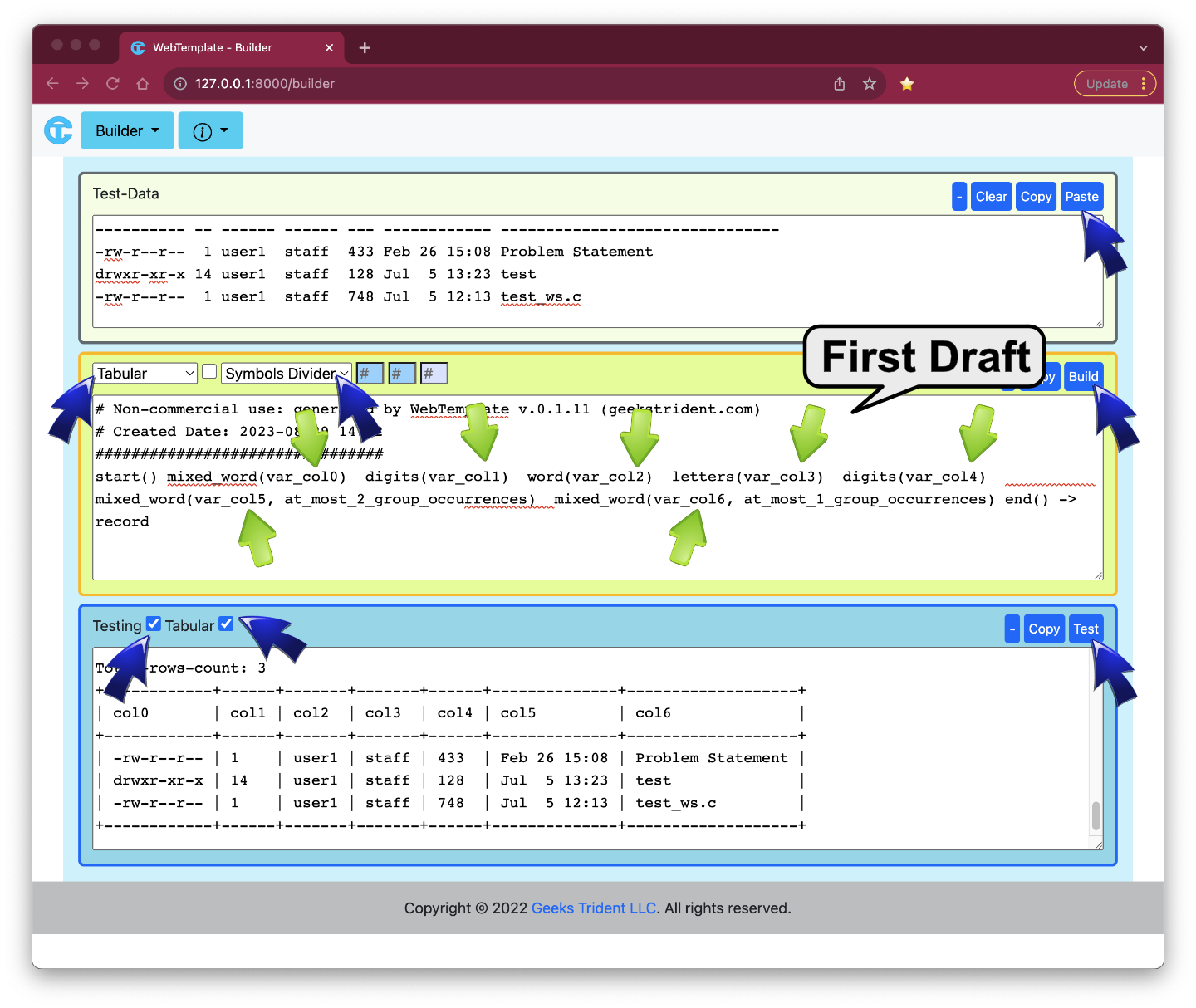
Next, user1 uses WebTemplate - Builder to build a first draft
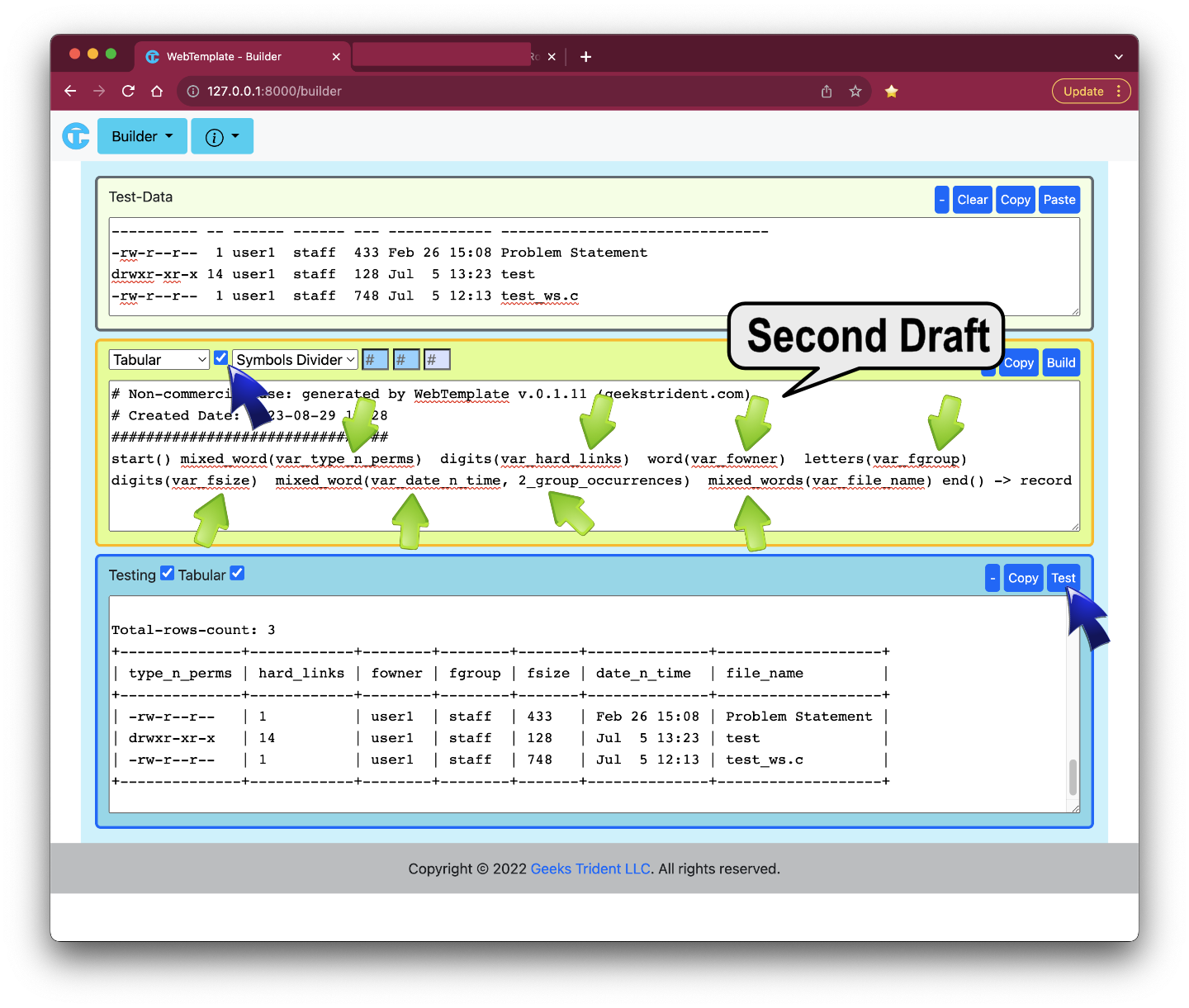
 User1 is unsure how to name columns and needs suggestion to properly parse data. User1 asks reviewer or data owner for helps. The ANSWER MIGHT BE
User1 is unsure how to name columns and needs suggestion to properly parse data. User1 asks reviewer or data owner for helps. The ANSWER MIGHT BE
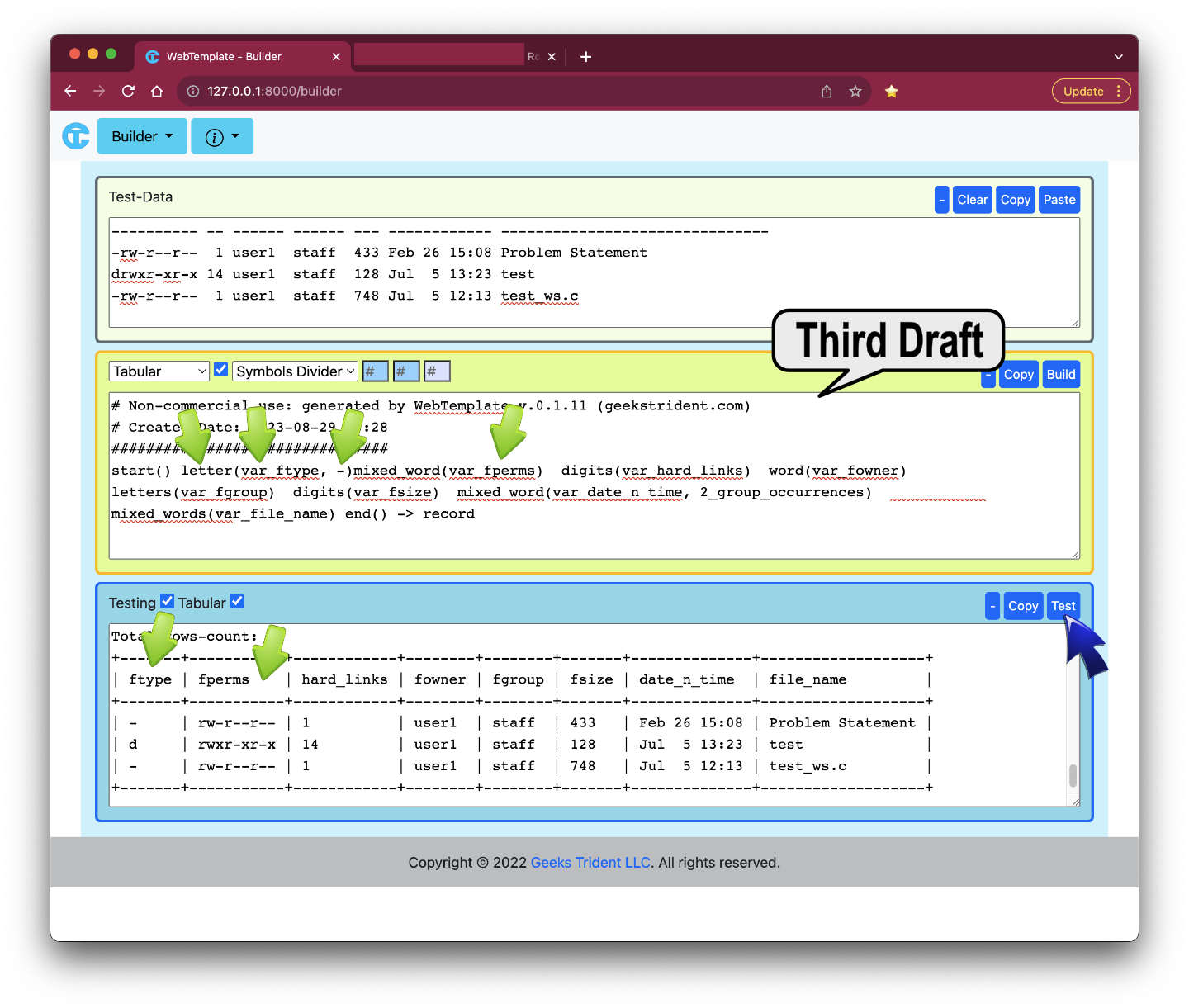
 After completed the second draft, user1 sends result to reviewer for reviewing. The ANSWER COULD BE
After completed the second draft, user1 sends result to reviewer for reviewing. The ANSWER COULD BE
 Furthermore, reviewer REQUESTS user1 to make a modification to match this particular output
Furthermore, reviewer REQUESTS user1 to make a modification to match this particular output
And, the fourth draft can be
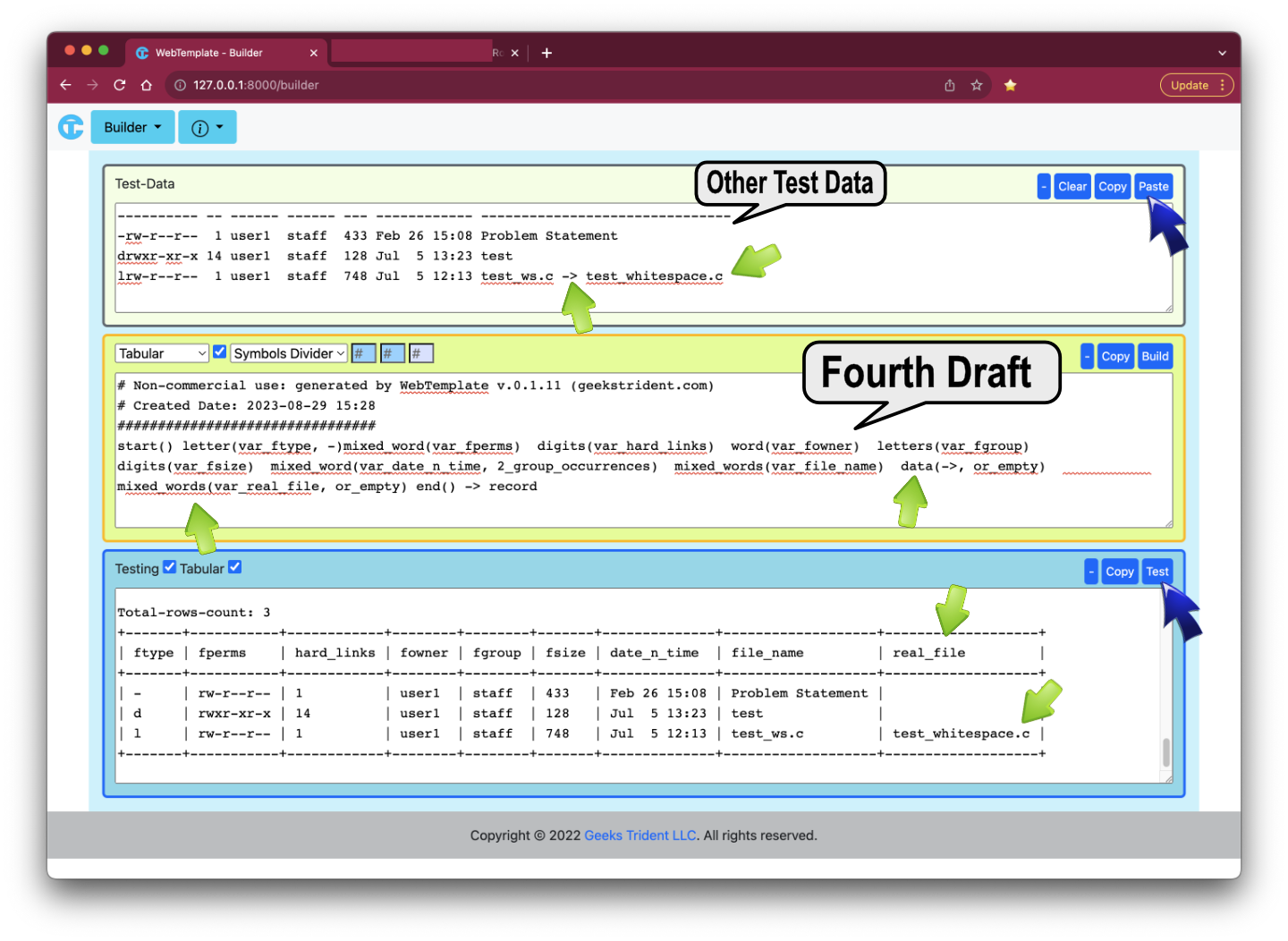
Assuming the fourth draft is the final solution. Therefore, communication and resolving problem have performed by using plain text language which might reduce confusion or improve clarification because technical work has simplified to human readable problem.
FIRST DRAFT
FINAL SOLUTION (i.e., 4th DRAFT)
And, the technical TextFSM template which is generated from user template snippet is
Unintended Memory Based Error (Lapse)
Assuming user1 is given an assignment to create a TextFSM template to parse the given output. The template should be able to parse values of name, description, pid, vid, and sn.
Assuming user1 wants to use WebTemplate application to solve this problem. User1 analyzes the output and find out that the first line has two categories: name and description, and the second line has three categories: pid, vid, and sn. Therefore, a total number of categories using for this output is 3.
Iteration #1: Generated Snippet By Using Test Data
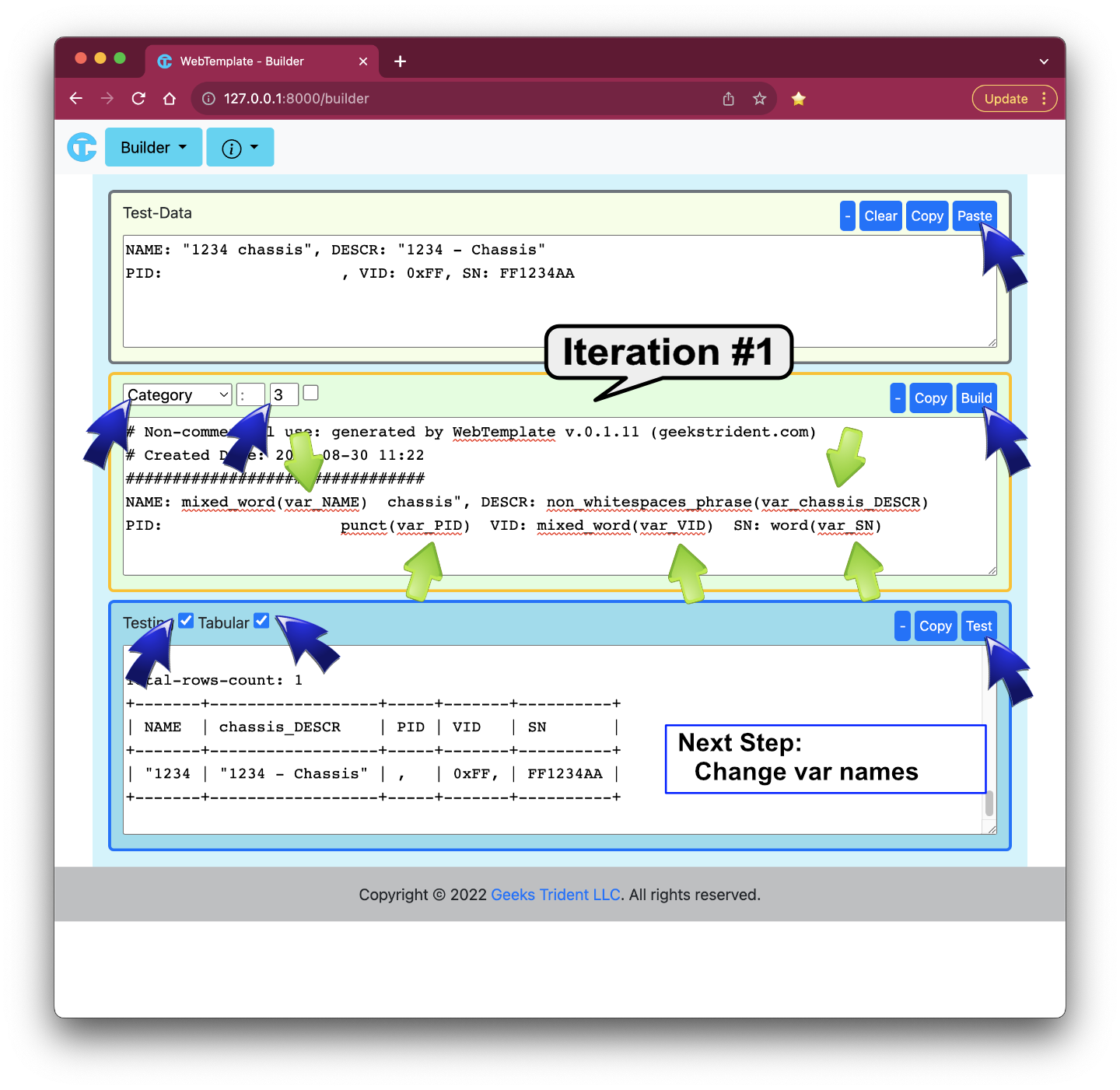
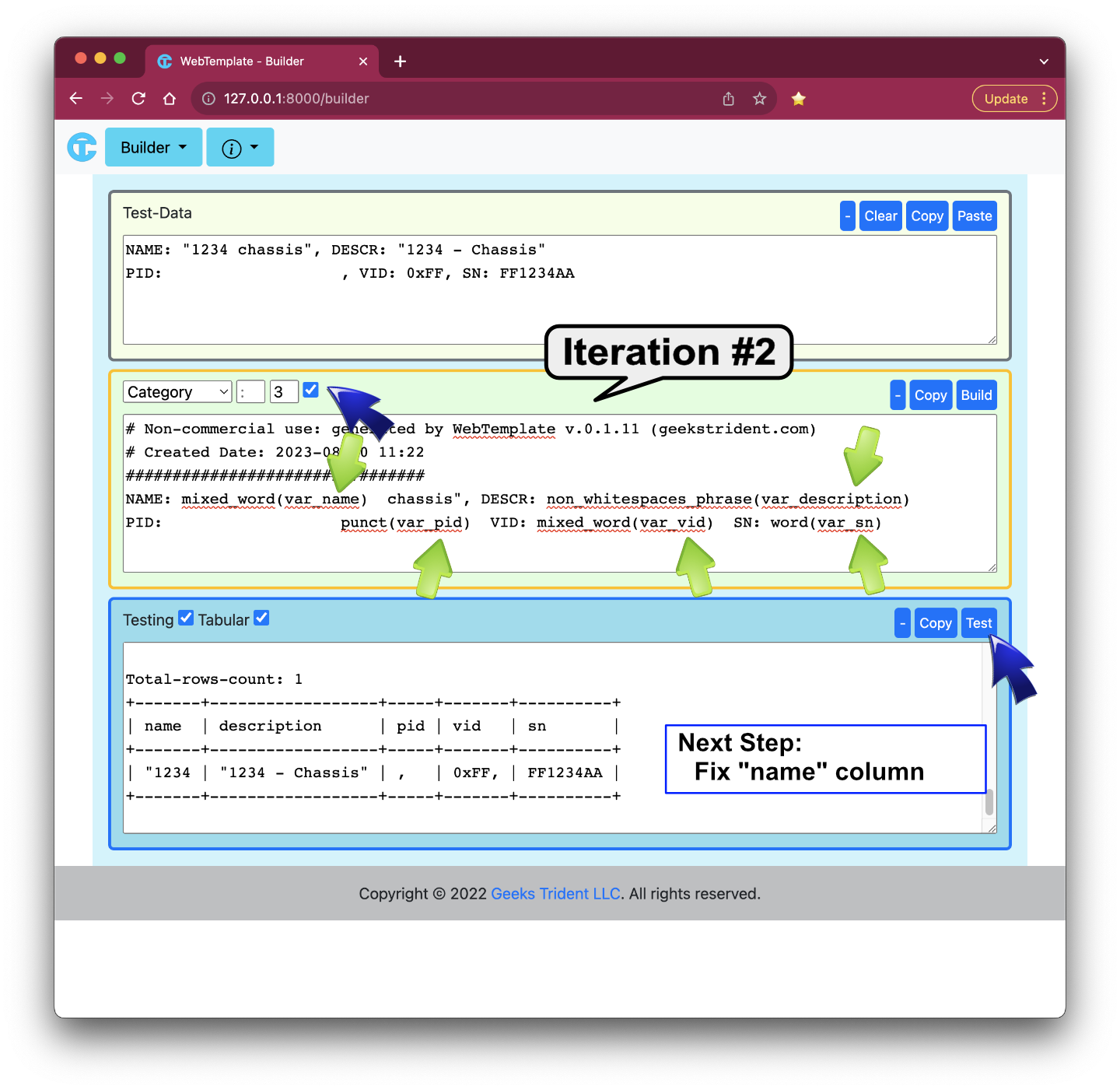
User1 observes that generated template snippet can parse most of data, but they are not expected results. The first step is to rename the proper variable names.
Iteration #2: Renaming Variables
Iteration #3: Fixing "name" Column
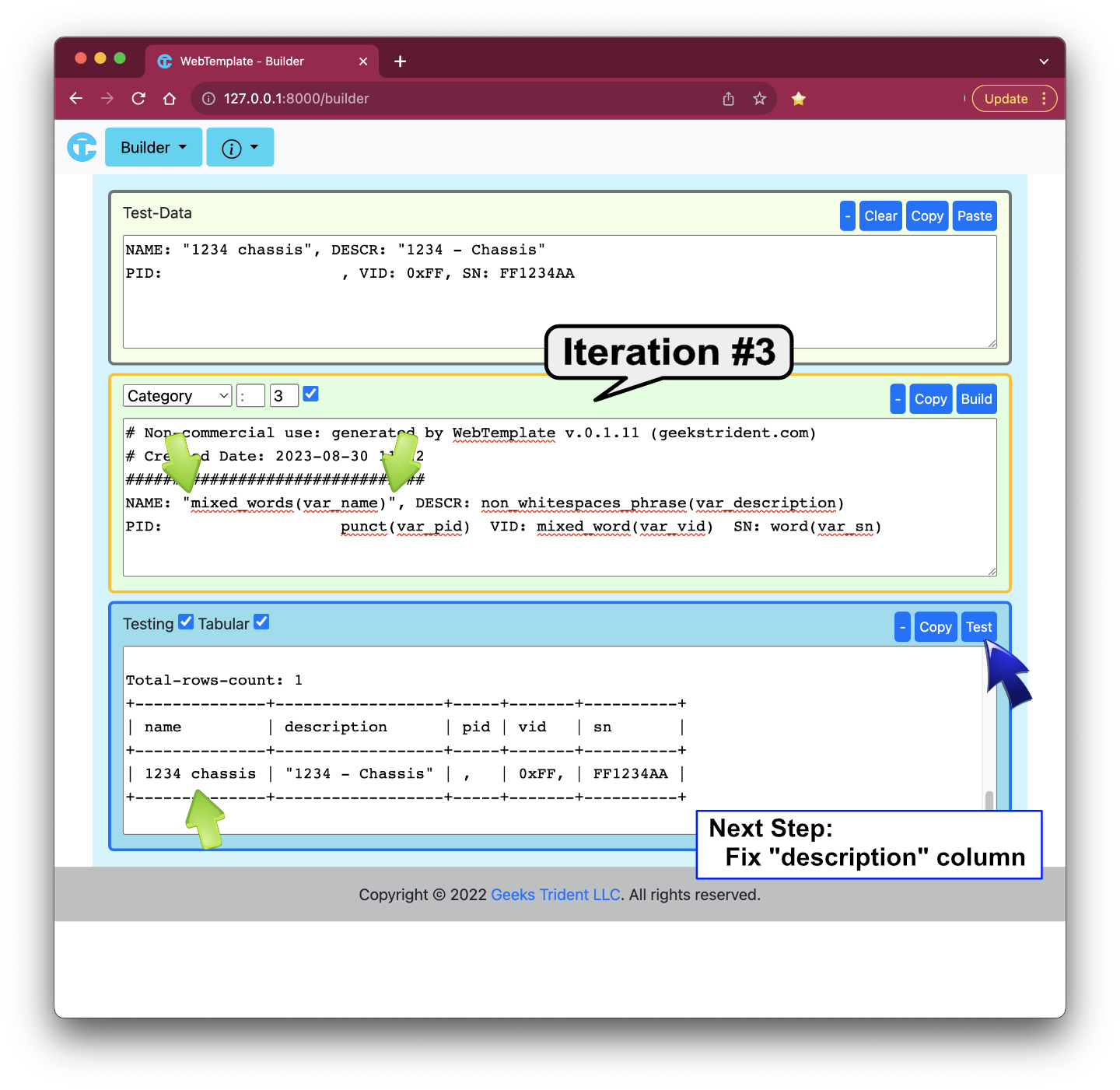
Iteration #4: Fixing "description" Column
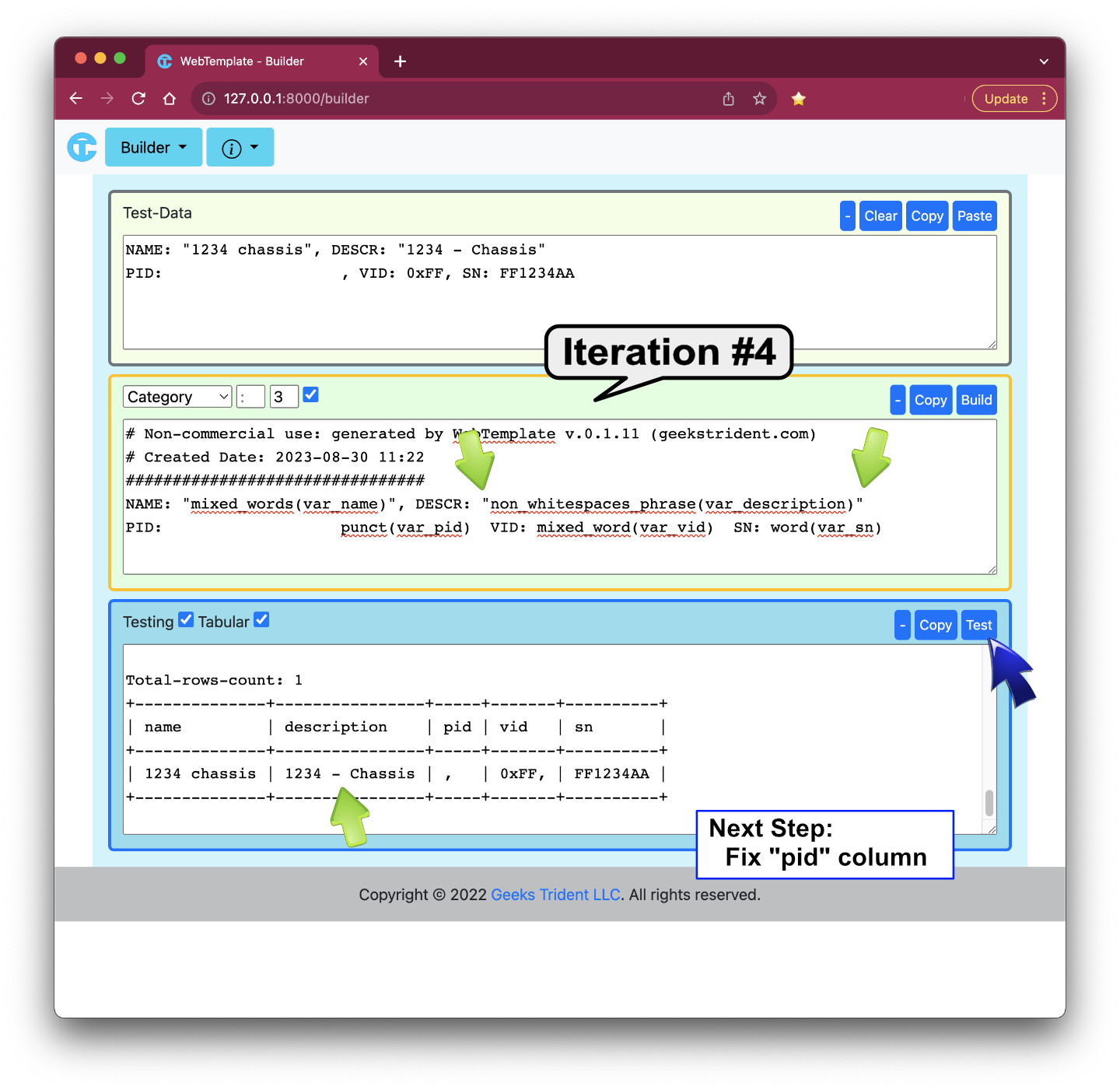
Iteration #5: Fixing "pid" Column
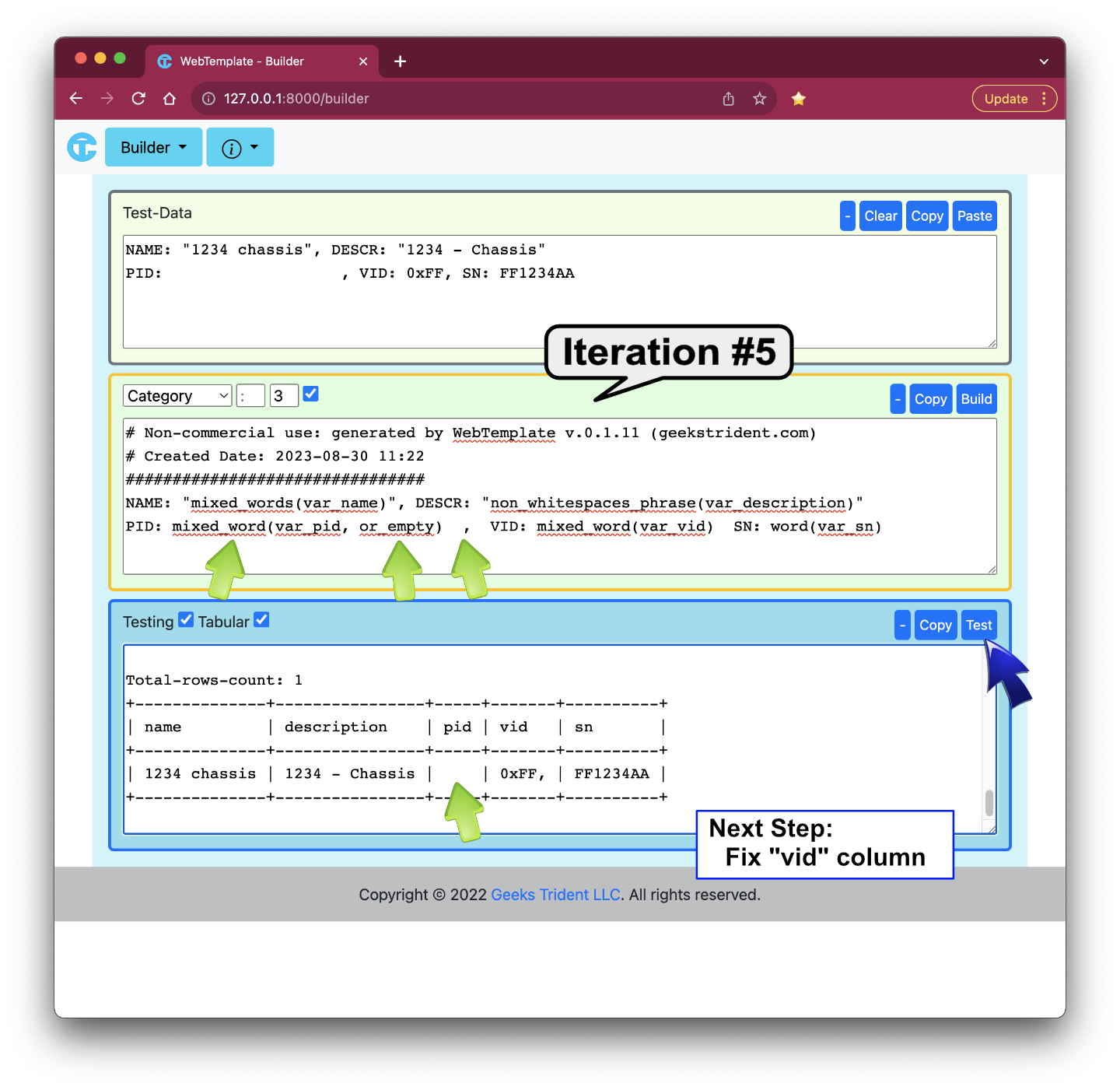
Iteration #6: Fixing "vid" Column
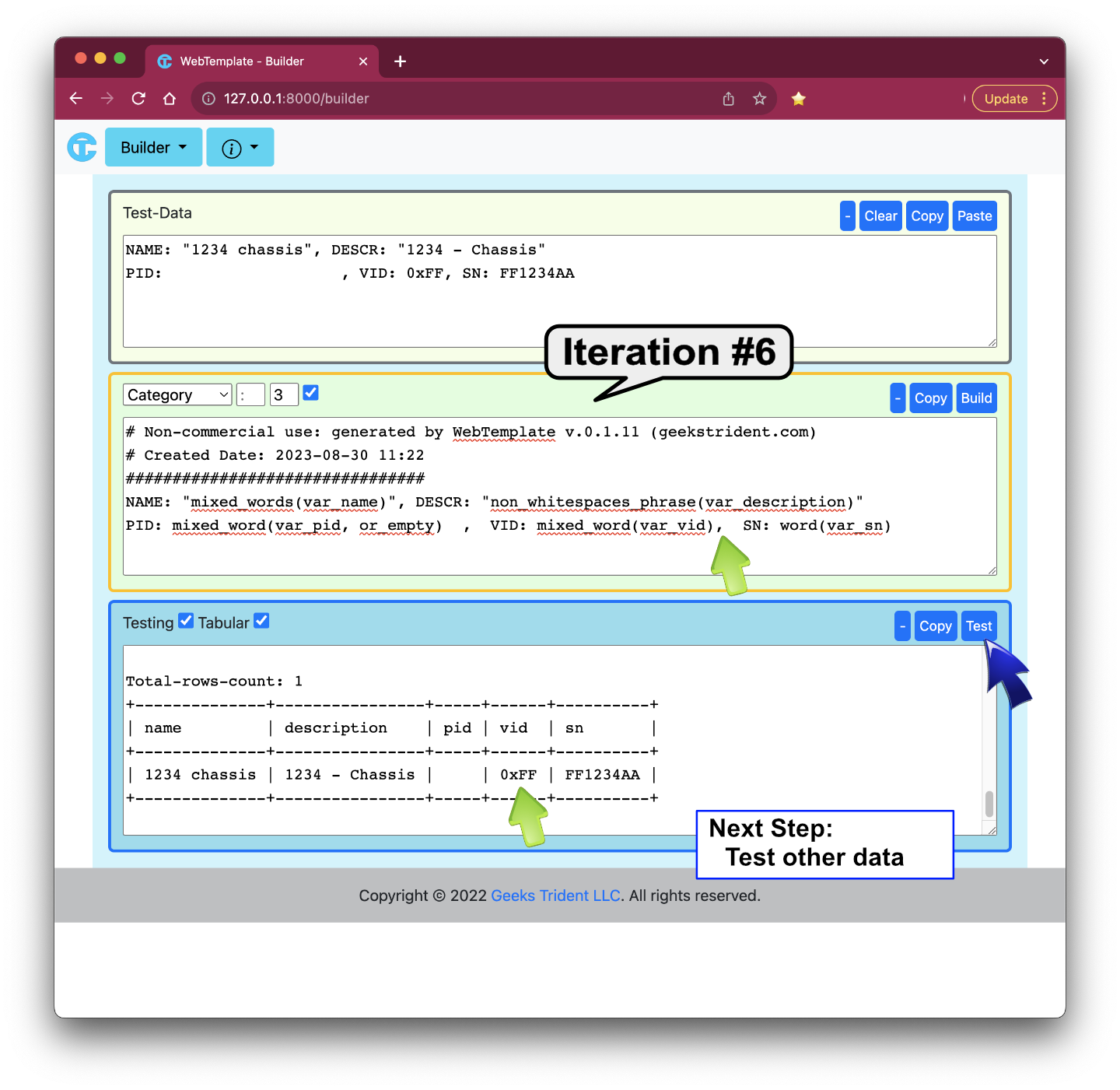
Iteration #7: Test Other Data By Using Generated Snippet
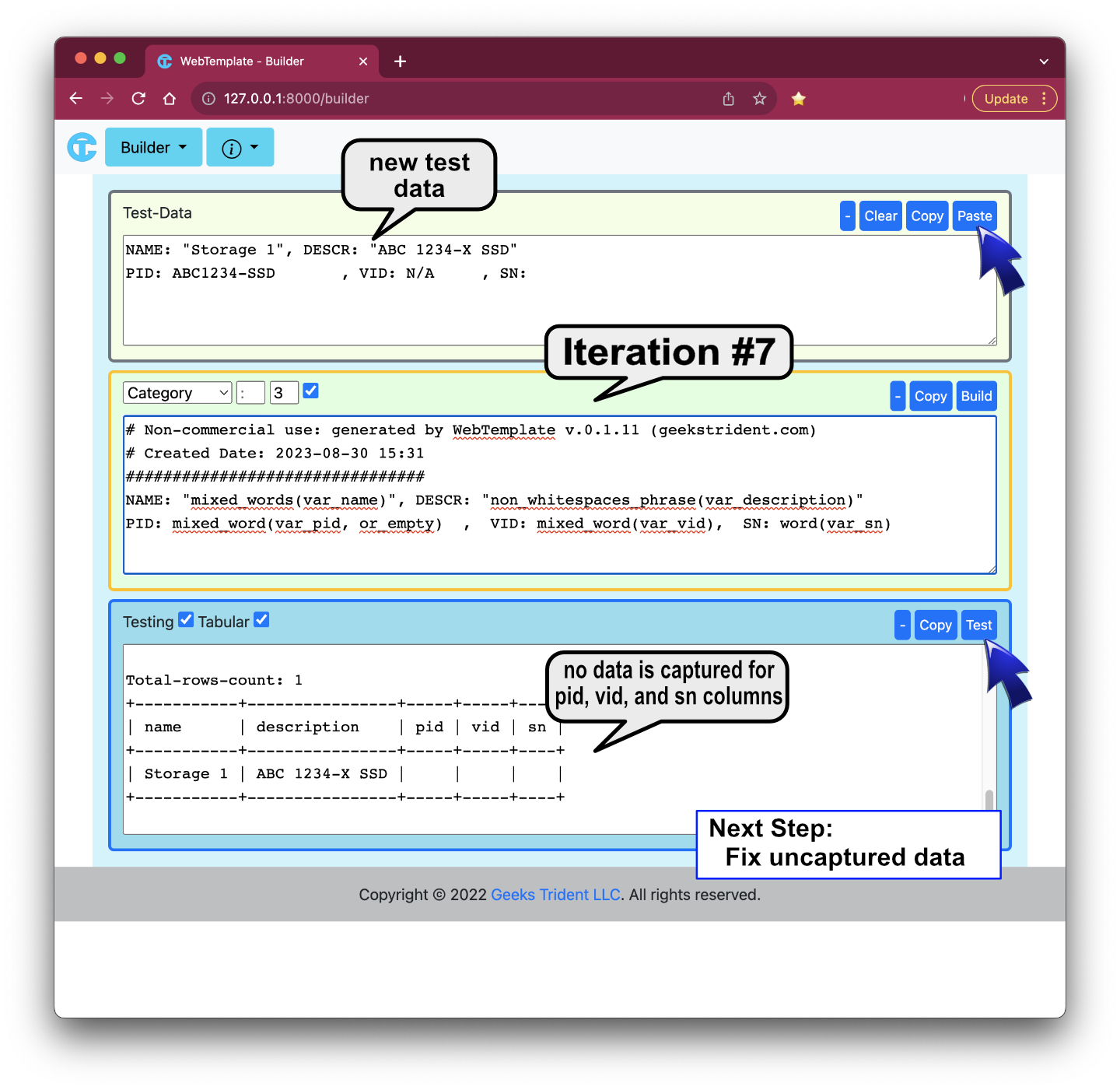
Iteration #8: Fixing Uncaptured Data for "pid", "vid", and "sn" columns
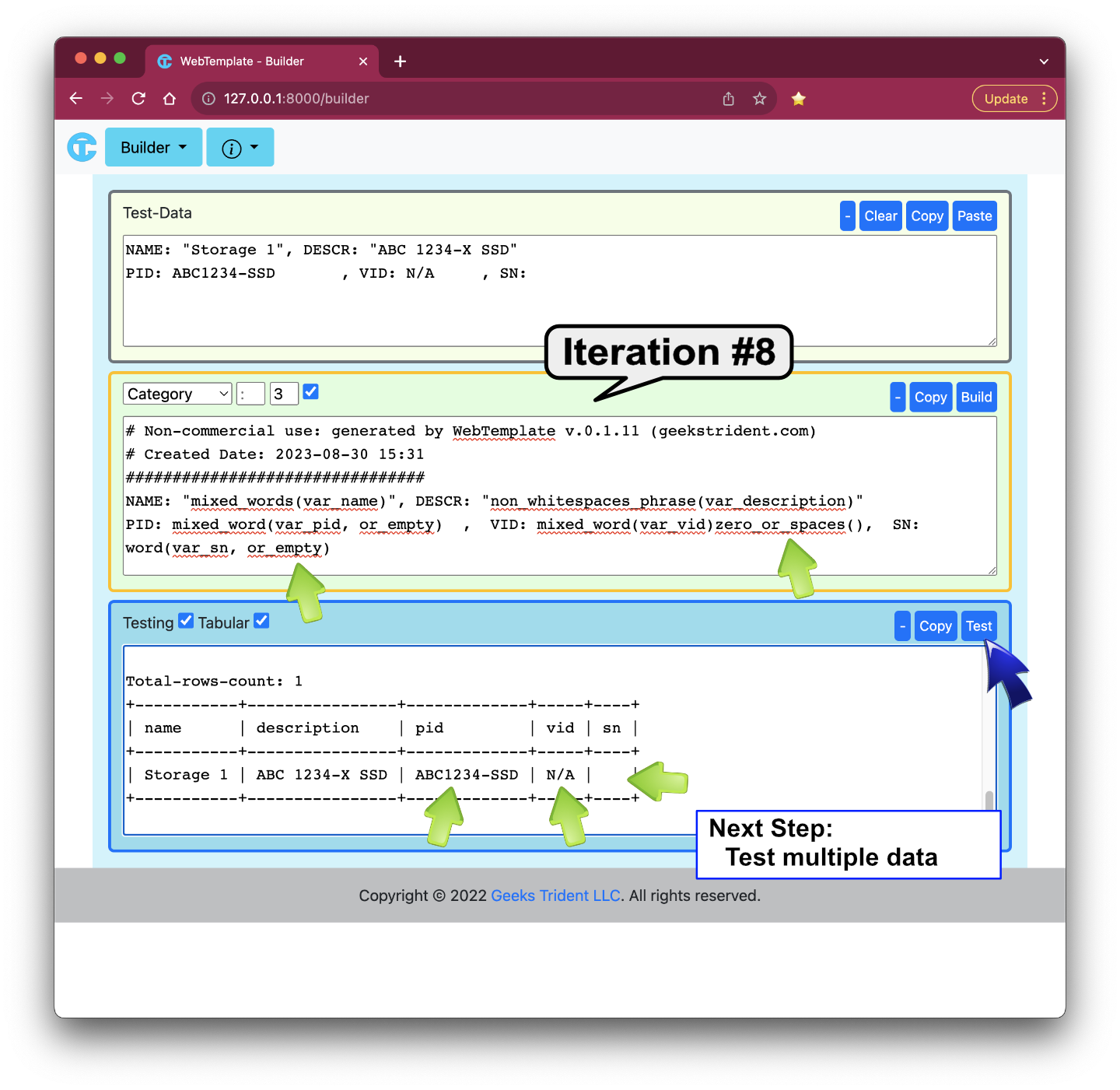
Iteration #9: Improving and Running Multiple Test Data
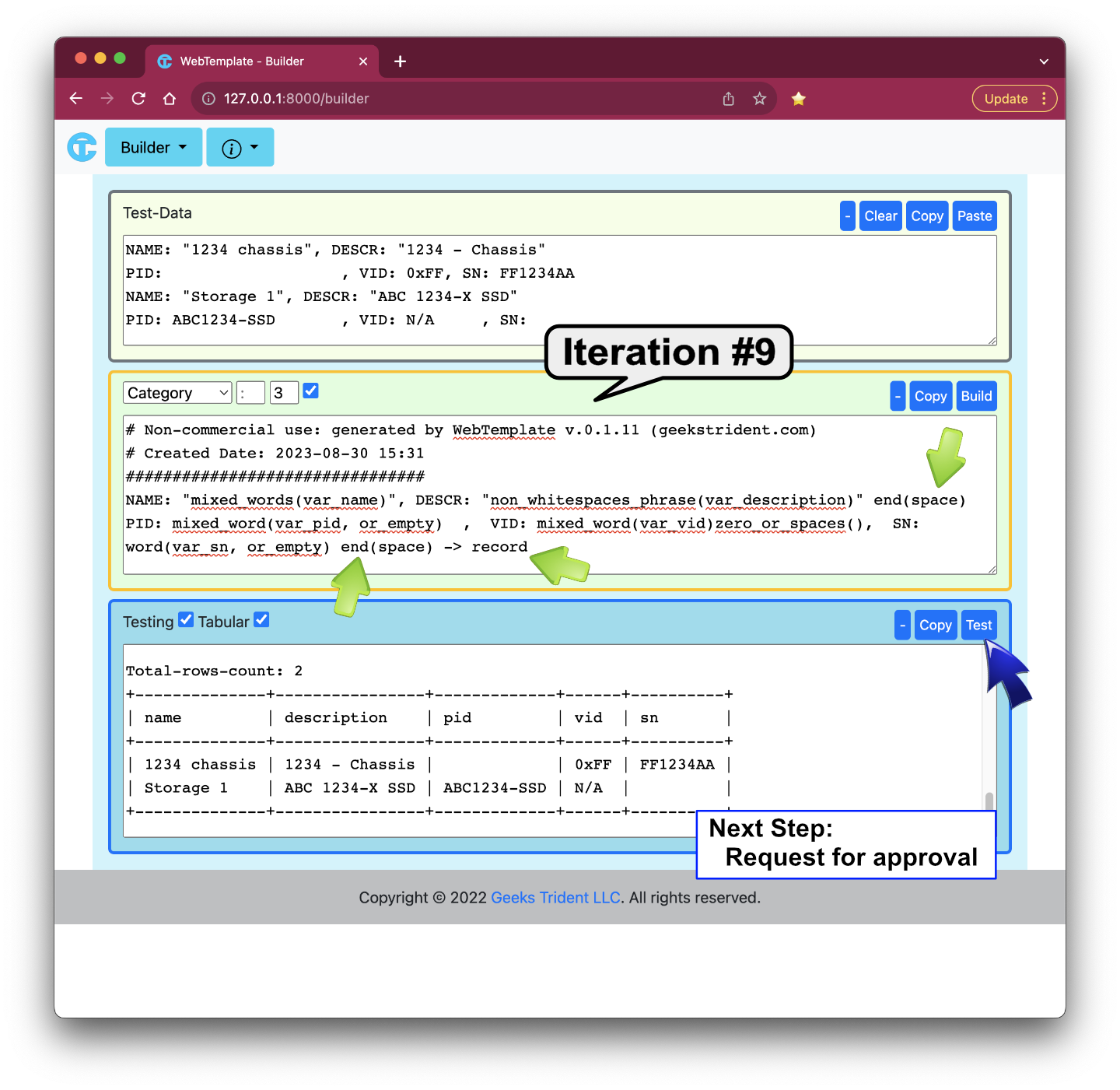
Assuming the 9th iteration is the final solution. It should be proficient work if there is a verification process for designing or solving problem to reduce guessing or to make assumption.
Intended Error
This type of error can be
- Intended Rule Based Mistake
- Intended Knowledge Based Mistake
- Human Use Error
- Latent Error
- ...
and, the practical approach of software development process are
- Quality Assurance
- Collaboration
- Risk Management
- Security
- Reliability
- Consistency
- Proficiency
- Scalability
- Extensibility
- Portability
- Continuous Improvement
- ...
TemplateApp needs to collaborate with other services to build high-quality software products.
Reusing Resource
Reusing Test Data
TemplateApp Builder - Differential
Differential feature lets end-user to build generic TextFSM template based on multiple different data where format of data should be a combination of <UNCHANGED-TEXT> and <CHANGED-TEXT>.
To be able to build template snippet from test data by using TemplateApp Builder - Differential feature,
Step #1: Forming Generic Differential Format
Step #2: Modifying Test Data and Substituting Into New Format
Step #3: Modifying Variable Names, Roll Back Original Format, and Testing
TemplateApp Builder - Category
Category feature lets end-user to build generic TextFSM template based on a single category text where format of data should be
For example, assuming end-user wants to capture meats, fruits, and drinks values in this data set
Step #1: Preparing Parameters for Builder From Test Data
Step #2: Building Solution From Test Data and Testing
Step #3: Modifying Snippet and Retesting If Necessary
TemplateApp Builder - Tabular
Tabular feature lets end-user to build generic TextFSM template based on a single tabular data.
Regular Tabular Text
TemplateApp Builder - Tabular feature currently supports two user-marking types.
Case 1: Tabular Text with Long Value or Out of Boundary in First Column
Case 2: Tabular Text with Too Many Values in Last Column
TemplateApp Builder - Free Style
SHOULD BE AVAILABLE in BETA VERSION
TemplateApp Builder - Designing
SHOULD BE AVAILABLE in BETA VERSION
Low Learning Curve
TemplateApp employs principle of least effort to boost individuals to quickly recognize problem and confidently build solution. Builder features are generated GENERIC solution which is based on human analogy.
For example, assuming user1 has created a solution to parse the output of "ls - l" Linux command line such asSolution A: Using Separated Solution for Each Command
Solution B: Using Optimal Flexible Solution for Either ls -l or ls -T
Next example shall use deductive reasoning to troubleshot problem.
Assuming end-user group finds some added-value in TextFSM template and really want to apply it to improve quality and productivity for their products. However, end-user group faces some challengesStudying Test Data #1
Studying Test Data #2
Studying Test Data #1.1 - with Comment Column
Reviewing Test Result of #1.1
Studying Test Data #2.1 - with Comment Column
Reviewing Test Result of #2.1
test_data_1 ---------- a b comment -------- ------- -------------------- val1.1 val1.2 first_line_has_all_values val2.2 second line has 1st empty cell. val3.1 third line has 2nd empty cell. val4.1 val4.2 fourth line has all values. val5.1 fifth line has 2nd empty cell. user_snippet_1 ---------- a b comment start() mixed_word(var_a)spaces()mixed_word(var_b)spaces()mixed_words(var_comment) end() -> record start() mixed_word(var_a)space()space(repetition_8_11)space()mixed_words(var_comment) end() -> record start() space(repetition_7_9)space()mixed_word(var_b)spaces()mixed_words(var_comment) end() -> record
test_data_2 ---------- a b comment -------- ------- -------------------- val1.1 1.2 first_line_has_all_values 2.2 second line has 1st empty cell. val3.1 third line has 2nd empty cell. val4.1 4.2 fourth line has all values. val5.1 fifth line has 2nd empty cell. user_snippet_2 ---------- a b comment start() mixed_word(var_a)spaces()number(var_b)spaces()mixed_words(var_comment) end() -> record start() mixed_word(var_a)space()space(repetition_8_11)space()mixed_words(var_comment) end() -> record start() space(repetition_7_9)space()number(var_b)spaces()mixed_words(var_comment) end() -> record
Problem XYZ system takes pair(test_data_1, user_snippet1) and expect to produce below result +--------+--------+---------------------------------+ | a | b | comment | +--------+--------+---------------------------------+ | val1.1 | val1.2 | first_line_has_all_values | | | val2.2 | second line has 1st empty cell. | | val3.1 | | third line has 2nd empty cell. | | val4.1 | val4.2 | fourth line has all values. | | val5.1 | | fifth line has 2nd empty cell. | +--------+--------+---------------------------------+ but the actual result is that some values are removed from "comment" column and those removed values are inserted into "b" column. +--------+--------+---------------------------------+ | a | b | comment | +--------+--------+---------------------------------+ | val1.1 | val1.2 | first_line_has_all_values | | | val2.2 | second line has 1st empty cell. | | val3.1 | third | line has 2nd empty cell. | | val4.1 | val4.2 | fourth line has all values. | | val5.1 | fifth | line has 2nd empty cell. | +--------+--------+---------------------------------+ XYZ system takes pair(test_data_2, user_snippet2) and expect to produce below result +--------+-----+---------------------------------+ | a | b | comment | +--------+-----+---------------------------------+ | val1.1 | 1.2 | first_line_has_all_values | | | 2.2 | second line has 1st empty cell. | | val3.1 | | third line has 2nd empty cell. | | val4.1 | 4.2 | fourth line has all values. | | val5.1 | | fifth line has 2nd empty cell. | +--------+-----+---------------------------------+ good news is that XYZ system produces the expected result.
test_data_2 a b comment -------- ------- -------------------- ... val3.1 third line has 2nd empty cell. ... val5.1 fifth line has 2nd empty cell. user_snippet_2 ---------- start() mixed_word(var_a) spaces() number(var_b) spaces() mixed_words(var_comment) end() start() mixed_word(var_a) space() space(repetition_8_11) space() mixed_words(var_comment) end() start() space(repetition_7_9) space() number(var_b) spaces() mixed_words(var_comment) end()
test_data_1 a b comment -------- ------- -------------------- ... val3.1 third line has 2nd empty cell. ... val5.1 fifth line has 2nd empty cell. user_snippet_1 ---------- start() mixed_word(var_a) spaces() mixed_word(var_b) spaces() mixed_words(var_comment) end() start() mixed_word(var_a) space() space(repetition_8_11) space() mixed_words(var_comment) end() start() space(repetition_7_9) space() mixed_word(var_b) spaces() mixed_words(var_comment) end()
Lucy analyses blank-spaces definition: spaces is interpreted as matching at least one blank space, or matching one or more spaces. In logic thinking, "at least one ..." or "one or more ... " implies "as many as possible", or "infinite quantities" Lucy adds notes: start() mixed_word(var_a) spaces(<infinite quantities>) mixed_word(var_b) spaces(<infinite quantities>) mixed_words(var_comment) end() ... start() mixed_word(var_a) spaces(<infinite quantities>) number(var_b) spaces(<infinite quantities>) mixed_words(var_comment) end()
Drawback
The main purpose of TemplateApp application is to simplify a process of building TextFSM template to improve code quality. Most features are designed to solve specific problem relating to human error, wasting resources, or complex training. Experience individuals with solid knowledge of building TextFSM template who rely too much on TemplateApp MUST BE a result of lowering design or creating TextFSM template over time.
Understanding RegexApp Keywords
There are three types of keywords: reserved keyword, system keywords, and user keywords. These keywords associate with keyword arguments to enhance matching or capturing capacity.
Reserved Keywords
- start
- an indicator keyword to generate regex pattern to match at the beginning of string. Its keyword arguments are: space, spaces, ws, whitespace, or whitespaces.
- Usage
- start() or start(ws) start(space) or start(spaces) start(whitespace) or start(whitespaces)
- Example
-
start()
should generate
"^"
start(space) should generate "^ *"
start(spaces) should generate "^ +"
start(ws) should generate r"^\s*"
start(whitespace) should generate r"^\s*"
start(whitespaces) should generate r"^\s+"
- end
- an indicator keyword to generate regex pattern to match at the end of string. Its keyword arguments are: space, spaces, ws, whitespace, or whitespaces.
- Usage
- end() or end(ws) end(space) or end(spaces) end(whitespace) or end(whitespaces)
- Example
-
end()
should generate
"$"
end(space) should generate " *$"
end(spaces) should generate " +$"
end(ws) should generate r"\s*$"
end(whitespace) should generate r"\s*$"
end(whitespaces) should generate r"\s+$"
- data
- an matching or capturing keyword to generate regex pattern to match or to capture raw data. Its keyword arguments should be similar to system keyword arguments.
- Usage
- data(<raw_data>) data(var_<name>, <raw_data>, <other_arguments>)
- Example
-
data(..) data(var_v1, ++>passed, word_bound_right)
should generate
r"\.\. (?P<v1>(\+\+>passed)\b)"
>>> >>> import re >>> test_data = ".. ++>passed" >>> # assuming generated pattern is >>> pattern = r"\.\. (?P<v1>(\+\+>passed)" >>> match = re.search(pattern, test_data) >>> print(match) <re.Match object; span=(0, 12), match='.. ++>passed'> >>> print(match.groupdict()) {'v1': '++>passed'} >>>
- end
- an matching or capturing keyword to generate regex pattern to match or to capture predefined symbols. Its keyword arguments should be similar to system keyword arguments.
- Usage
- symbol(name=<symbol_name>) symbol(var_<name>, name=<symbol_name>, <other_arguments>)
- Example
-
start() symbol(name=dot, 5_occurrences) symbol(name=hyphen, at_least_3_occurrence) end()
should generate
r"^\.{5} +-{3,}$"
The generated pattern should match this "..... ----------" data.
The generated pattern should not match this "........ ----------" data.
System Keywords
- Usage
- <keyword>(var_<name>, <other_data,...>, or_empty, or_<other_keywords>, <keyword_arguments>)
- Example #1
-
digits()
is a format of
<keyword>()which should match at least one numeric.
Its generated pattern is r"\d+".
- Example #2
-
digits(N/A)
is a format of
<keyword>(<other_data,...>)which should match at least one numeric or N/A data.
Its generated pattern is r"\d+|N/A".
- Example #3
-
digits(var_v1, N/A)
is a format of
<keyword>(var_<name>, <other_data,...>)which should capture at least one numeric or N/A data, and then store in v1 variable.
Its generated pattern is r"(?P<v1>\d+|N/A)".
- Example #4
-
digits(var_v1, or_empty)
is a format of
<keyword>(var_<name>, or_empty)which should capture at least one numeric or empty data and then store in v1 variable.
Its generated pattern is r"(?P<v1>\d+|)".>>> import re >>> >>> # start() Food: word(var_food, or_empty) Total: digits(var_total, N/A) end() >>> # Assuming pattern is generated from above user data snippet >>> pattern = r"^Food:\s*(?P<food>[a-zA-Z][a-zA-Z0-9]*|) +Total: (?P<total>\d+|N/A)$" >>> >>> test_data = """ ... Food: Mango Total: 159 ... Food: Total: N/A ... """.strip() >>> >>> for line in test_data.splitlines(): ... match = re.search(pattern, line) ... if match: ... print(match.groupdict()) ... {'food': 'Mango', 'total': '159'} {'food': '', 'total': 'N/A'} >>>
- Example #5
-
ipv4_addr(var_addr, or_mac_addr)
is a format of
<keyword>(var_<name>, or_<other_keyword>)which should capture either IPv4 address or MAC address, and then store in addr variable.
Its generated pattern is r"^Address: (?P<addr>\d{1,3}([.]\d{1,3}){3}|([0-9a-fA-F]{2}([: -][0-9a-fA-F]{2}){5})) *$".>>> # start() Address: ipv4_addr(var_addr, or_mac_addr) end(space) >>> # Assuming pattern is generated from above user data snippet >>> pattern = r"^Address: (?P<addr>\d{1,3}([.]\d{1,3}){3}|([0-9a-fA-F]{2}([: -][0-9a-fA-F]{2}){5})) *$" >>> >>> test_data = """ ... Address: 192.168.1.1 ... Address: AA:11:BB:22:CC:33 ... """.strip() >>> >>> import re >>> >>> for line in test_data.splitlines(): ... match = re.search(pattern, line) ... if match: ... print(match.groupdict()) ... {'addr': '192.168.1.1'} {'addr': 'AA:11:BB:22:CC:33'} >>>
- Example #6
-
letters(var_v1, 5_occurrence)
is a format of
<keyword>(var_<name>, <keyword_arguments>)which should match at least one numeric.
Its generated pattern is r"(?P<v1>[a-zA-Z]{5})".
User Keywords
These keywords are created by users and stored in ~/.geekstrident/regexpro/user_references.yaml file on deployed system. Keywords MUST NOT DUPLICATE reserved and system keywords. Future version should provide an option to let users store or access user keyword by using database. The usage of user keywords is similar to the usage of system keywords.
Keyword Arguments
Categories: capturing, alternation, repetition, occurrences, group-occurrences, word-bound, head, tail, and to-do-list.
- var_<name>
-
encapsulate keyword pattern with (?P<name>...). It should let regex store matching data to variable.
word(var_v1) should generate r"(?P<v1>[a-zA-Z][a-zA-Z0-9]*)" and store matching word to v1 variable.
- or_empty
-
join keyword pattern and empty string with
|
separator, and then encapsulate result with parenthesis, i.e.,
(...|).
It should let regex match zero or pattern.
word(or_empty) should generate r"([a-zA-Z][a-zA-Z0-9]*|)" that should match a word or an empty string.
- or_<other_keyword>
-
join keyword pattern and other-keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(...|...).
It should let regex match either keyword pattern or other keyword pattern.
time(or_number, format4) should generate r"(\d{2}:\d{2})|((\d+)?[.]?\d+)" that should match a number or time value of format 4 HH:MM.
- or_<datum>
<datum> -
join keyword pattern and datum with
|
separator.
Case 1: no enclosed parenthesis if data is singular form, i.e.,...|data1|data2|data_n.
digits(or_n/a, or_null, or_none) should generate r"(\d+)|n/a|null|none".
digits(n/a, null, none) should generate r"(\d+)|n/a|null|none".
Case 2: with enclosed parenthesis if data is plural form, i.e., (...|(data 1)|data2|data_n).
digits(or_n/a, or_not applicable) should generate r"((\d+)|n/a|(not applicable))".
digits(n/a, not applicable) should generate r"((\d+)|n/a|(not applicable))".
- or_repeat_k_space
or_k_space -
join
( {k})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {k})|...).
word(var_v1, or_repeat_5_space) should generate r"(?P<v1>( {5})|([a-zA-Z][a-zA-Z0-9]*))".
word(var_v1, or_5_space) should generate r"(?P<v1>( {5})|([a-zA-Z][a-zA-Z0-9]*))".
- or_repeat_m_n_space
-
join
( {m,n})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {m,n})|...).
word(var_v1, or_repeat_2_5_space) should generate r"(?P<v1>( {2,5})|([a-zA-Z][a-zA-Z0-9]*))".
- or_repeat__n_space
or_at_most_n_space -
join
( {,n})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {,n})|...).
word(var_v1, or_repeat__5_space) should generate r"(?P<v1>( {,5})|([a-zA-Z][a-zA-Z0-9]*))".
word(var_v1, or_at_most_5_space) should generate r"(?P<v1>( {,5})|([a-zA-Z][a-zA-Z0-9]*))".
- or_repeat_m__space
or_at_least_m_space -
join
( {m,})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {m,})|...).
word(var_v1, or_repeat_2__space) should generate r"(?P<v1>( {2,})|([a-zA-Z][a-zA-Z0-9]*))".
word(var_v1, or_at_least_5_space) should generate r"(?P<v1>( {2,})|([a-zA-Z][a-zA-Z0-9]*))".
- or_either_repeat_k_space
or_either_k_space -
join
( {k})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {k})| *... *).
word(var_v1, or_either_repeat_5_space) should generate r"(?P<v1>( {5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
word(var_v1, or_either_5_space) should generate r"(?P<v1>( {5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
- or_either_repeat_m_n_space
-
join
( {m,n})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {m,n})| *... *).
word(var_v1, or_either_repeat_2_5_space) should generate r"(?P<v1>( {2,5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
- or_either_repeat__n_space
or_either_at_most_n_space -
join
( {,n})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {,n})| *... *).
word(var_v1, or_either_repeat__5_space) should generate r"(?P<v1>( {,5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
word(var_v1, or_either_at_most_5_space) should generate r"(?P<v1>( {,5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
- or_either_repeat_m__space
or_either_at_least_m_space -
join
( {m,})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {m,})| *... *).
word(var_v1, or_either_repeat_2__space) should generate r"(?P<v1>( {2,})|( *[a-zA-Z][a-zA-Z0-9]* *))".
word(var_v1, or_either_at_least_5_space) should generate r"(?P<v1>( {2,})|( *[a-zA-Z][a-zA-Z0-9]* *))".
- repeat_k
-
append {k} to keyword pattern which transform to match exact k-time.
letter(var_v1, repetition_5) should generate r"(?P<v1>[a-zA-Z]{5})".
- repeat_m _n
-
append {m,n} to keyword pattern which transform to match at least m-time and at most n-time.
letter(var_v1, repetition_2_5) should generate r"(?P<v1>[a-zA-Z]{2,5})".
- repeat__n
-
append {,n} to keyword pattern which transform to match at most n-time.
letter(var_v1, repetition__5) should generate r"(?P<v1>[a-zA-Z]{,5})".
- repeat_m_
-
append {m,} to keyword pattern which transform to match at least m-time.
letter(var_v1, repetition_2_) should generate r"(?P<v1>[a-zA-Z]{2,})".
- k_occurrence
-
if k = 0, append ? to keyword pattern which transform to match zero or one matching.
if k = 1, is to match itself.
if k > 1, append {k} to keyword pattern which transform to match k-times.
letter(var_v1, 0_occurrence) should generate r"(?P<v1>[a-zA-Z]?)".
letter(var_v1, 1_occurrence) should generate r"(?P<v1>[a-zA-Z])".
letter(var_v1, 5_occurrence) should generate r"(?P<v1>[a-zA-Z]{5})".
- 0_or_1_occurrence
-
append
?
to keyword pattern which transform to match zero or one.
letter(var_v1, 0_or_1_occurrence) should generate r"(?P<v1>[a-zA-Z]?)".
- k_or_more_occurrence
-
if k = 0, append * to keyword pattern which transform to match zero or more matching.
if k = 1, append + to keyword pattern which transform to match at least one matching.
if k > 1, append {k,} to keyword pattern which transform to match at least k-times.
letter(var_v1, 0_or_more_occurrence) should generate r"(?P<v1>[a-zA-Z]*)".
letter(var_v1, 1_or_more_occurrence) should generate r"(?P<v1>[a-zA-Z]+)".
letter(var_v1, 3_or_more_occurrence) should generate r"(?P<v1>[a-zA-Z]{3,})".
- at_least_m_occurrence
-
if m = 0, append * to keyword pattern which transform to match zero or more matching.
if m >= 1, append {m,} to keyword pattern which transform to match at least m-times.
letter(var_v1, at_least_0_occurrence) should generate r"(?P<v1>[a-zA-Z]*)".
letter(var_v1, at_least_3_occurrence) should generate r"(?P<v1>[a-zA-Z]{3,})".
- at_most_n_occurrence
-
if n = 0, append ? to keyword pattern which transform to match zero or one matching.
if n >= 1, append {,n} to keyword pattern which transform to match at most n-times.
letter(var_v1, at_most_0_occurrence) should generate r"(?P<v1>[a-zA-Z]?)".
letter(var_v1, at_most_8_occurrence) should generate r"(?P<v1>[a-zA-Z]{,8})".
- k_phrase_occurrence
k_group_occurrence -
if k = 0, append ( ...)? or ( +...)? to keyword pattern which transform to match one or two matching.
if k = 1, append ( ...) or ( +...) to keyword pattern which transform to match exact two matching.
if k > 1, append ( ...){k,} or ( +...){k,} to keyword pattern which transform to match exact (k + 1) matching.
word(0_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)?".
word(0_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)?".
word(1_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)".
word(1_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)".
word(5_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*){5}".
word(5_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*){5}".
- 0_or_1_phrase_occurrence
0_or_1_group_occurrence -
append ( ...)? or ( +...)? to keyword pattern which transform to match one or two matching.
word(0_or_1_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)?".
word(0_or_1_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)?".
- k_or_more_phrase_occurrence
k_or_more_group_occurrence -
if k = 0, append ( ...)* or ( +...)* to keyword pattern which transform to match at least one matching.
if k = 1, append ( ...)+ or ( +...)+ to keyword pattern which transform to match at least two matching.
if k > 1, append ( ...){k,} or ( +...){k,} to keyword pattern which transform to match at least (k + 1) matching.
word(0_or_more_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)*".
word(0_or_more_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)*".
word(1_or_more_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)+".
word(1_or_more_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)+".
word(5_or_more_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*){5,}".
word(5_or_more_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*){5,}".
- at_least_m_phrase_occurrence
at_least_m_group_occurrence -
if m = 0, append ( ...)* or ( +...)* to keyword pattern which transform to match at least one matching.
if m >= 1, append ( ...){m,} or ( +...){m,} to keyword pattern which transform to match at least (m + 1) matching.
word(at_least_0_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)*".
word(at_least_0_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)*".
word(at_least_5_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*){5,}".
word(at_least_5_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*){5,}".
- at_most_n_phrase_occurrence
at_most_n_group_occurrence -
if n = 0, append ( ...)? or ( +...)? to keyword pattern which transform to match at most one or two matching.
if n >= 1, append ( ...){,n} or ( +...){,n} to keyword pattern which transform to match at most (n + 1) matching.
word(at_most_0_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)?".
word(at_most_0_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)?".
word(at_most_5_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*){,5}".
word(at_most_5_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*){,5}".
- word_bound_left
-
prepend \b to the beginning of keyword pattern. It should let regex perform word bound on left matching.
word(word_bound_left) should generate r"\b[a-zA-Z][a-zA-Z0-9]*".
- word_bound_right
-
append \b to the end of keyword pattern. It should let regex perform word bound on right matching.
word(word_bound_right) should generate r"[a-zA-Z][a-zA-Z0-9]*\b".
- word_bound
-
enclose \b around keyword pattern. It should let regex perform word bound on matching.
word(word_bound) should generate r"\b[a-zA-Z][a-zA-Z0-9]*\b".
- head
-
prepend ^ to keyword pattern which inform regex engine that pattern should start at the beginning of string.
word(head) should generate r"^[a-zA-Z][a-zA-Z0-9]*".
- head_ws
head_whitespace -
prepend ^\\s* to keyword pattern which inform regex engine that pattern should start at the beginning of string with zero or some whitespaces.
word(head_whitespace) should generate r"^\s*[a-zA-Z][a-zA-Z0-9]*".
- head_ws_plus
head_whitespaces
head_whitespace_plus -
prepend ^\\s+ to keyword pattern which inform regex engine that pattern should start at the beginning of string with some whitespaces.
word(head_whitespaces) should generate r"^\s+[a-zA-Z][a-zA-Z0-9]*".
- head_space
-
prepend ^ * to keyword pattern which inform regex engine that pattern should start at the beginning of string with zero or some blank-space.
word(head_space) should generate r"^ *[a-zA-Z][a-zA-Z0-9]*".
- head_spaces
head_space_plus -
prepend ^ + to keyword pattern which inform regex engine that pattern should start at the beginning of string with some blank-space.
word(head_spaces) should generate r"^ +[a-zA-Z][a-zA-Z0-9]*".
- head_just_ws
head_just_whitespace -
prepend \\s* to keyword pattern which transform to match zero or some whitespaces and then pattern.
word(head_just_whitespace) should generate r"\s*[a-zA-Z][a-zA-Z0-9]*".
- head_just_ws_plus
head_just_whitespaces
head_just_whitespace_plus -
prepend \\s+ to keyword pattern which transform to match some whitespaces and then pattern.
word(head_just_whitespaces) should generate r"\s+[a-zA-Z][a-zA-Z0-9]*".
- head_just_space
-
prepend * to keyword pattern which transform to match zero or some blank-space and then pattern.
word(head_just_space) should generate r" *[a-zA-Z][a-zA-Z0-9]*".
- head_just_spaces
head_just_space_plus -
prepend + to keyword pattern which transform to match some blank-space and then pattern.
word(head_just_spaces) should generate r" +[a-zA-Z][a-zA-Z0-9]*".
- tail
-
append $ to keyword pattern which inform regex engine that stop matching after seeing pattern.
word(tail) should generate r"[a-zA-Z][a-zA-Z0-9]*$".
- tail_ws
tail_whitespace -
append \\s*$ to keyword pattern which inform regex engine that stop matching after seeing pattern and zero or some whitespaces.
word(tail_whitespace) should generate r"[a-zA-Z][a-zA-Z0-9]*\s*$".
- tail_ws_plus
tail_whitespaces
tail_whitespace_plus -
prepend \\s+$ to keyword pattern which inform regex engine that stop matching after seeing pattern and some whitespaces.
word(tail_whitespaces) should generate r"[a-zA-Z][a-zA-Z0-9]*\s+$".
- tail_space
-
prepend *$ to keyword pattern which inform regex engine that stop matching after seeing pattern and zero or some blank-space.
word(tail_space) should generate r"[a-zA-Z][a-zA-Z0-9]* *$".
- tail_spaces
tail_space_plus -
append +$ to keyword pattern which inform regex engine that stop matching after seeing pattern and some blank-space.
word(tail_spaces) should generate r"[a-zA-Z][a-zA-Z0-9]* +$".
- tail_just_ws
tail_just_whitespace -
append \\s* to keyword pattern which transform to match pattern and then zero or some whitespaces.
word(tail_just_whitespace) should generate r"[a-zA-Z][a-zA-Z0-9]*\s*".
- tail_just_ws_plus
tail_just_whitespaces
tail_just_whitespace_plus -
append \\s+ to keyword pattern which transform to match pattern and then some whitespaces
word(tail_just_whitespaces) should generate r"[a-zA-Z][a-zA-Z0-9]*\s+".
- tail_just_space
-
append * to keyword pattern which transform to match pattern and zero or some blank-space.
word(tail_just_space) should generate r"[a-zA-Z][a-zA-Z0-9]* *".
- tail_just_spaces
tail_just_space_plus -
append + to keyword pattern which transform to match pattern and then some blank-space.
word(tail_just_spaces) should generate r"[a-zA-Z][a-zA-Z0-9]* +".
- ?
-
To Be Announced
letter(var_v1, ?) should generate r"(?P<v1>[a-zA-Z]?)".
- *
-
To Be Announced
letter(var_v1, *) should generate r"(?P<v1>[a-zA-Z]*)".
- +
-
To Be Announced
letter(var_v1, +) should generate r"(?P<v1>[a-zA-Z]+)".
- {k}
-
To Be Announced
letter(var_v1, {0) should generate r"(?P<v1>[a-zA-Z]?)".
letter(var_v1, {1) should generate r"(?P<v1>[a-zA-Z])".
letter(var_v1, {5) should generate r"(?P<v1>[a-zA-Z]{5})".
- {m,n}
-
To Be Announced
letter(var_v1, {,5) should generate r"(?P<v1>[a-zA-Z]{,5})".
letter(var_v1, {2,) should generate r"(?P<v1>[a-zA-Z]{2,})".
letter(var_v1, {2,5) should generate r"(?P<v1>[a-zA-Z]{2,5})".
- phrase?
group? -
To Be Announced
letters(var_v1, phrase?) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+)?)".
letters(var_v1, group?) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+)?)".
- phrase*
group* -
To Be Announced
letters(var_v1, phrase*) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+)*)".
letters(var_v1, group*) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+)*)".
- phrase+
group+ -
To Be Announced
letters(var_v1, phrase+) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+)+)".
letters(var_v1, group+) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+)+)".
- phrase{k}
group{k} -
To Be Announced
letters(var_v1, phrase{0}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+)?)".
letters(var_v1, group{0}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+)?)".
letters(var_v1, phrase{1}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+))".
letters(var_v1, group{1}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+))".
letters(var_v1, phrase{5}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+){5})".
letters(var_v1, group{5}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+){5})".
- phrase{m,n}
group{m,n} -
To Be Announced
letters(var_v1, phrase{2,}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+){2,})".
letters(var_v1, group{2,}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+){2,})".
letters(var_v1, phrase{,5}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+){,5})".
letters(var_v1, group{,5}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+){,5})".
letters(var_v1, phrase{2,5}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+){2,5})".
letters(var_v1, group{2,5}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+){2,5})".
- or_space?
or_ws?
or_whitespace?
or_either_space?
or_either_ws?
or_either_whitespace? -
To Be Announced
letters(var_v1, or_space?) should generate r"(?P<v1>( ?)|([a-zA-Z]+))".
letters(var_v1, or_whitespace?) should generate r"(?P<v1>(\s?)|([a-zA-Z]+))".
letters(var_v1, or_either_space?) should generate r"(?P<v1>( ?)|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace?) should generate r"(?P<v1>(\s?)|( *[a-zA-Z]+ *))".
- or_space*
or_ws*
or_whitespace*
or_either_space*
or_either_ws*
or_either_whitespace* -
To Be Announced
letters(var_v1, or_space*) should generate r"(?P<v1>( *)|([a-zA-Z]+))".
letters(var_v1, or_whitespace*) should generate r"(?P<v1>(\s*)|([a-zA-Z]+))".
letters(var_v1, or_either_space*) should generate r"(?P<v1>( *)|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace*) should generate r"(?P<v1>(\s*)|( *[a-zA-Z]+ *))".
- or_space+
or_ws+
or_whitespace+
or_either_space+
or_either_ws+
or_either_whitespace+ -
To Be Announced
letters(var_v1, or_space+) should generate r"(?P<v1>( +)|([a-zA-Z]+))".
letters(var_v1, or_whitespace+) should generate r"(?P<v1>(\s+)|([a-zA-Z]+))".
letters(var_v1, or_either_space+) should generate r"(?P<v1>( +)|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace+) should generate r"(?P<v1>(\s+)|( *[a-zA-Z]+ *))".
- or_space{k}
or_ws{k}
or_whitespace{k}
or_either_space{k}
or_either_ws{k}
or_either_whitespace{k} -
To Be Announced
letters(var_v1, or_space{5}) should generate r"(?P<v1>( {5})|([a-zA-Z]+))".
letters(var_v1, or_whitespace{5}) should generate r"(?P<v1>(\s{5})|([a-zA-Z]+))".
letters(var_v1, or_either_space{5}) should generate r"(?P<v1>( {5})|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace{5}) should generate r"(?P<v1>(\s{5})|( *[a-zA-Z]+ *))".
- or_space{m,n}
or_ws{m,n}
or_whitespace{m,n}
or_either_space{m,n}
or_either_ws{m,n}
or_either_whitespace{m,n} -
To Be Announced
letters(var_v1, or_space{2,}) should generate r"(?P<v1>( {2,})|([a-zA-Z]+))".
letters(var_v1, or_whitespace{2,}) should generate r"(?P<v1>(\s{2,})|([a-zA-Z]+))".
letters(var_v1, or_either_space{2,}) should generate r"(?P<v1>( {2,})|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace{2,}) should generate r"(?P<v1>(\s{2,})|( *[a-zA-Z]+ *))".
letters(var_v1, or_space{,5}) should generate r"(?P<v1>( {,5})|([a-zA-Z]+))".
letters(var_v1, or_whitespace{,5}) should generate r"(?P<v1>(\s{,5})|([a-zA-Z]+))".
letters(var_v1, or_either_space{,5}) should generate r"(?P<v1>( {,5})|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace{,5}) should generate r"(?P<v1>(\s{,5})|( *[a-zA-Z]+ *))".
letters(var_v1, or_space{2,5}) should generate r"(?P<v1>( {2,5})|([a-zA-Z]+))".
letters(var_v1, or_whitespace{2,5}) should generate r"(?P<v1>(\s{2,5})|([a-zA-Z]+))".
letters(var_v1, or_either_space{2,5}) should generate r"(?P<v1>( {2,5})|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace{2,5}) should generate r"(?P<v1>(\s{2,5})|( *[a-zA-Z]+ *))".
How Does It Work?